Organizations handling import/export operations rely on accurate and efficient document processing to comply with regulatory requirements and maintain seamless operations. Intelligent Document Processing (IDP) plays a vital role in automating this process, but challenges such as low-quality inputs, multilingual content, and domain-specific terminology can hinder accuracy. This article explores how to optimize IDP for documents like the Hong Kong Import Declaration Form 1, aiming to improve accuracy rates from 85% to 95% or beyond.

1. Harness Domain Knowledge to Improve Data Extraction
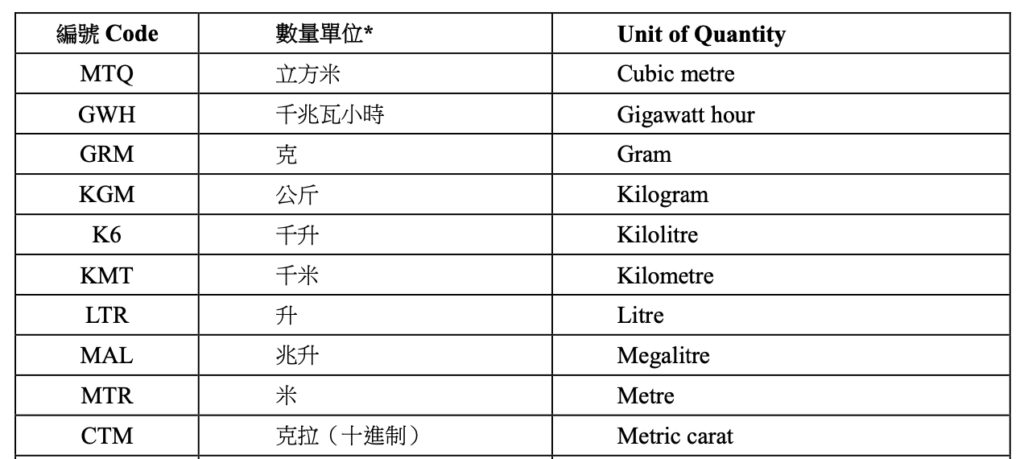
IDP systems can significantly benefit from embedding domain-specific knowledge relevant to import/export processes. For example, the provided declaration form includes structured fields such as Transport Modes and Units of Quantity, which are critical for regulatory compliance. By incorporating these into your system’s knowledge base, you can enhance contextual understanding and reduce classification errors.
Classification of Transport Modes
Classification of Units of Quantity
2. Enable Instant Learning Through User Interaction
One of the most effective ways to improve IDP accuracy is to enable real-time learning through user corrections. When users review a document and adjust errors, these corrections act as immediate training signals for the engine. This feedback loop allows the system to continuously adapt to specific data patterns and organizational preferences, driving consistent improvements with minimal intervention.
Quick Adaptation for Label Fields
Significant Enhancements in Line Item Extraction
For example, adjusting errors in columns like Commodity Code, Unit of Quantity, or CIF Values HK enables the engine to handle variations in table structures more effectively. A single correction on a misaligned table row can refine the system’s ability to extract similar line-item details in future cases.
This instant learning mechanism reduces the dependency on pre-compiled datasets and accelerates the path to higher accuracy.
3. Apply Spelling Correction for Low-Quality Inputs
Low-quality document inputs—such as scanned images with poor scan quality, handwritten text, or OCR-related extraction errors—pose a significant challenge for any IDP system. To address this, advanced spelling correction algorithms can play a vital role.
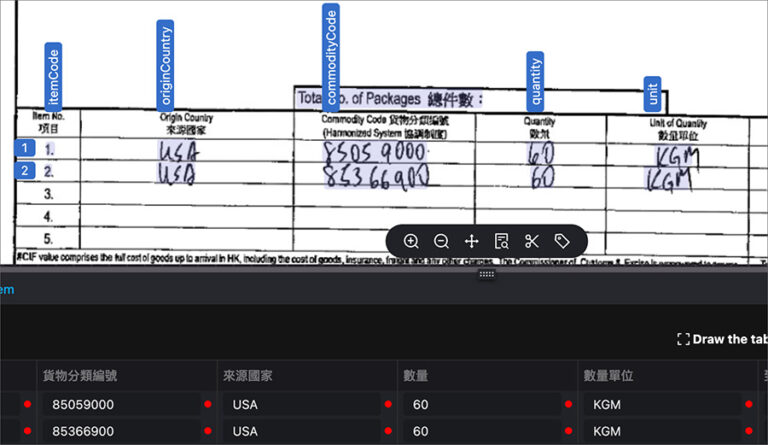
These mechanisms automatically detect and correct common issues, including:
- Misinterpretation of illegible characters.
- Incomplete text extraction caused by damaged or faded document areas.
- Typographical errors in source documents.
Through systematic implementation of these measures, IDP can not only achieve high accuracy but also establish sustainable development capabilities. This investment brings significant business returns: improved processing efficiency, reduced manual costs, and enhanced competitive advantage.
The key is to establish a complete technology-business feedback loop, enabling the system to continuously evolve and improve through practical applications. Only such an IDP solution can truly meet the ever-growing demands of enterprises.


